之前由于需要处理一些从网站数据库直接提取出的excel表格,进行去重和对相应单位的编号,所以有了这一次Excel数据清洗的经历。
下面就进行详细说明。
目的:
去重
编号
使用语言:python
涉及到的主要模块:
- xlrd
- Pandas
一、知识准备
1、Pandas介绍
python的数据分析包,是作为金融数据分析工具而被开发的,这里我们主要是利用pandas将excel表格数据转化为其中的数据结构DataFrame,从而将操作excel表变成操作DataFrame。
2、DataFrame
该数据结构是一个表格型的数据结构,包含一组有序的列,每列可以是不同的值类型。拥有行索引和列索引。 具体的关于DataFrame的操作这里给出一个比较好的使用说明,里面也有介绍Series的内容:Pandas使用指南
3、xlrd介绍
在这次数据经历的工作中还使用到了python中来读取和存储excel的扩展模块——xlrd。 它的作用来对本次处理的excel表格进行读取和存储,同时也可以实现指定表单、指定单元格的读写。
4、xlrd的基本操作
1)导入模块
import xlrd
2)打开Excel文件读取数据
data = xlrd.open_workbook('excelFile.xls')
3)使用技巧
获取一个工作表
table = data.sheets()[0] #通过索引顺序获取
table = data.sheet_by_index(0) #通过索引顺序获取
table = data.sheet_by_name(u'Sheet1') #通过名称获取
获取整行和整列的值(数组)
table.row_values(i)
table.col_values(i)
获取行数和列数
nrows = table.nrows
ncols = table.ncols
循环行列表数据
for i in range(nrows ):
print table.row_values(i)
单元格
cell_A1 = table.cell(0,0).value
cell_C4 = table.cell(2,3).value
使用行列索引
cell_A1 = table.row(0)[0].value
cell_A2 = table.col(1)[0].value
简单的写入
row = 0
col = 0
# 类型 0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error
ctype = 1 value = '单元格的值'
xf = 0 # 扩展的格式化
table.put_cell(row, col, ctype, value, xf)
table.cell(0,0) #单元格的值'
table.cell(0,0).value #单元格的值'
二、流程
这里主要说明一下整个数据清理的逻辑。
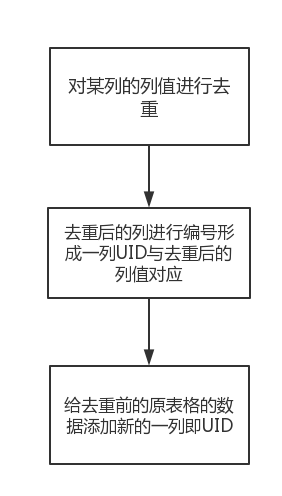
三、代码
其实这次清理的整个逻辑比较简单,涉及到的比较难的部分在于Pandas中DataFrame数据结构的使用。
1、去重
#filename: delete_dup.py
# -*- coding:utf-8 -*-
import pandas as pd
# 将excel文件转换为DataFrame
df = pd.DataFrame(pd.read_excel('excel_name.xlsx'))
# 删除对应列的重复值,保留第一次出现的位置
new_df = df.drop_duplicates('1', keep='first').dropna()
print 'drop ok!'
new_df.to_excel('excel_name_fix.xlsx')
2、编号并回填
#filename: build_tag.py
# -*- coding:utf-8 -*-
import pandas as pd
import xlrd
# 生成对应索引所需文件
data = xlrd.open_workbook('ROOT_TO_YOUR_FILE_FROM_LAST_CLEAN.xlsx')
table = data.sheet_by_index(0)
# 获取行数
nrows = table.nrows
# 键值对的信息格式为 —— 名字:UID
UID = {}
# 这样会包含第一行列名的信息,问题不大
# 第二列和第三列
# 第二列:第三列
for i in range(nrows):
UID[table.cell(i,1).value]=table.cell(i,2).value
###############################至此完成数据编号##################################
#################################下面进行回填###################################
# 待清洗数据
cleaning_data = pd.DataFrame(pd.read_excel('ROOT_TO_YOUR_FILE_TO_CLEAN.xlsx'))
# print cleaning_data
series_name = cleaning_data['UNAME']
# 生成索引
new_form = pd.Series(UID, index=series_name)
# 添加新列为索引值
cleaning_data['UID'] = new_form.values
cleaned_data = cleaning_data
# 调整列的顺序
UID = cleaned_data.pop('UID')
cleaned_data.insert(5, 'UID', UID)
# 写文件
cleaned_data.to_excel('ROOT_TO_STORE_YOUR_CLEANED_FILE.xlsx')
print 'ok'